Teachers and Examiners (CBSESkillEduction) collaborated to create the Natural Language Processing Class 10 Notes. All the important Information are taken from the NCERT Textbook Artificial Intelligence (417).
Natural Language Processing Class 10 Notes

NLP (Natural Language Processing), is dedicated to making it possible for computers to comprehend and process human languages. Artificial intelligence (AI) is a subfield of linguistics, computer science, information engineering, and artificial intelligence that studies how computers interact with human (natural) languages, particularly how to train computers to handle and analyze massive volumes of natural language data.
Applications of Natural Language Processing
Most people utilize NLP apps on a regular basis in their daily lives. Following are a few examples of real-world uses for natural language processing:
Automatic Summarization – Automatic summarization is useful for gathering data from social media and other online sources, as well as for summarizing the meaning of documents and other written materials.
Sentiment Analysis – To better comprehend what internet users are saying about a company’s goods and services, businesses use natural language processing tools like sentiment analysis to understand the customer requirement.
Indicators of their reputation – Sentiment analysis goes beyond establishing simple polarity to analyse sentiment in context to help understand what is behind an expressed view. This is very important for understanding and influencing purchasing decisions.
Text classification – Text classification enables you to classify a document and organise it to make it easier to find the information you need or to carry out certain tasks. Spam screening in email is one example of how text categorization is used.
Virtual Assistants – These days, digital assistants like Google Assistant, Cortana, Siri, and Alexa play a significant role in our lives. Not only can we communicate with them, but they can also facilitate our life.
Chatbots
A chatbot is one of the most widely used NLP applications. Many chatbots on the market now employ the same strategy as we did in the instance above. Let’s test out a few of the chatbots to see how they function.
• Mitsuku Bot*
https://www.pandorabots.com/mitsuku/
• CleverBot*
https://www.cleverbot.com/
• Jabberwacky*
http://www.jabberwacky.com/
• Haptik*
https://haptik.ai/contact-us
• Rose*
http://ec2-54-215-197-164.us-west-1.compute.amazonaws.com/speech.php
• Ochatbot*
https://www.ometrics.com/blog/list-of-fun-chatbots/
There are 2 types of chatbots
- Scriptbot
- Smart-bot.
| Scriptbot | Smart-bot |
|---|---|
| Script bots are easy to make | Smart-bots are flexible and powerful |
| Script bots work around a script which is programmed in them | Smart bots work on bigger databases and other resources directly |
| Mostly they are free and are easy to integrate to a messaging platform | Smart bots learn with more data |
| No or little language processing skills | Coding is required to take this up on board |
| Limited functionality | Wide functionality |
Human Language VS Computer Language
Humans need language to communicate, which we constantly process. Our brain continuously processes the sounds it hears around us and works to make sense of them. Our brain continuously processes and stores everything, even as the teacher is delivering the lesson in the classroom.
The Computer Language is understood by the computer, on the other hand. All input must be transformed to numbers before being sent to the machine. And if a single error is made while typing, the machine throws an error and skips over that area. Machines only use extremely simple and elementary forms of communication.
Data Processing
Data Processing is a method of manipulation of data. It means the conversion of raw data into meaningful and machine-readable content. It basically is a process of converting raw data into meaningful information.
Since human languages are complex, we need to first of all simplify them in order to make sure that the understanding becomes possible. Text Normalisation helps in cleaning up the textual data in such a way that it comes down to a level where its complexity is lower than the actual data. Let us go through Text Normalisation in detail.
Text Normalisation
The process of converting a text into a canonical (standard) form is known as text normalisation. For instance, the canonical form of the word “good” can be created from the words “gooood” and “gud.” Another illustration is the reduction of terms that are nearly identical, such as “stopwords,” “stop-words,” and “stop words,” to just “stopwords.”
Sentence Segmentation
Under sentence segmentation, the whole corpus is divided into sentences. Each sentence is taken as a different data so now the whole corpus gets reduced to sentences.
Tokenisation
Sentences are first broken into segments, and then each segment is further divided into tokens. Any word, number, or special character that appears in a sentence is referred to as a token. Tokenization treats each word, integer, and special character as a separate entity and creates a token for each of them.
Removing Stopwords, Special Characters and Numbers
In this step, the tokens which are not necessary are removed from the token list. What can be the possible words which we might not require?
Stopwords are words that are used frequently in a corpus but provide nothing useful. Humans utilise grammar to make their sentences clear and understandable for the other person. However, grammatical terms fall under the category of stopwords because they do not add any significance to the information that is to be communicated through the statement. Stopwords include a, an, and, or, for, it, is, etc.
Converting text to a common case
After eliminating the stopwords, we change the text’s case throughout, preferably to lower case. This makes sure that the machine’s case-sensitivity does not treat similar terms differently solely because of varied case usage.
Stemming
The remaining words are boiled down to their root words in this step. In other words, stemming is the process of stripping words of their affixes and returning them to their original forms.
Lemmatization
Stemming and lemmatization are alternate techniques to one another because they both function to remove affixes. However, lemmatization differs from both of them in that the word that results from the elimination of the affix (also known as the lemma) is meaningful.

Bag of Words
A bag-of-words is a textual illustration that shows where words appear in a document. There are two components: a collection of well-known words. a metric for the amount of well-known words.
A Natural Language Processing model called Bag of Words aids in the extraction of textual information that can be used by machine learning techniques. We gather the instances of each term from the bag of words and create the corpus’s vocabulary.
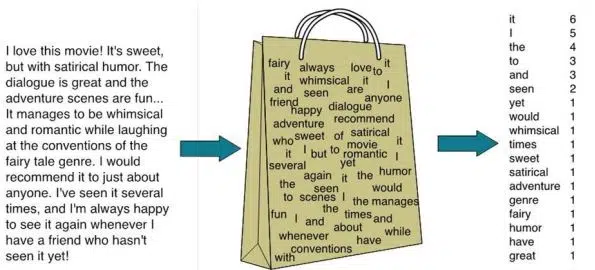
Here is the step-by-step approach to implement bag of words algorithm:
1. Text Normalisation: Collect data and pre-process it
2. Create Dictionary: Make a list of all the unique words occurring in the corpus. (Vocabulary)
3. Create document vectors: For each document in the corpus, find out how many times the word from the unique list of words has occurred.
4. Create document vectors for all the documents.
Term Frequency
The measurement of a term’s frequency inside a document is called term frequency. The simplest calculation is to count the instances of each word. However, there are ways to change that value based on the length of the document or the frequency of the term that appears the most often.
Inverse Document Frequency
A term’s frequency inside a corpus of documents is determined by its inverse document frequency. It is calculated by dividing the total number of documents in the corpus by the number of documents that contain the phrase.
Applications of TFIDF
TFIDF is commonly used in the Natural Language Processing domain. Some of its applications are:
| Document Classification | Topic Modelling | Information Retrieval System | Stop word filtering |
|---|---|---|---|
| Helps in classifying the type and genre of a document. | It helps in predicting the topic for a corpus. | To extract the important information out of a corpus. | Helps in removing the unnecessary words out of a text body. |
Employability skills Class 10 Notes
- Unit 1- Communication Skills Class 10 Notes
- Unit 2- Self-Management Skills Class 10 Notes
- Unit 3- Basic ICT Skills Class 10 Notes
- Unit 4- Entrepreneurial Skills Class 10 Notes
- Unit 5- Green Skills Class 10 Notes
Employability skills Class 10 MCQ
- Unit 1- Communication Skills Class 10 MCQ
- Unit 2- Self-Management Skills Class 10 MCQ
- Unit 3- Basic ICT Skills Class 10 MCQ
- Unit 4- Entrepreneurial Skills Class 10 MCQ
- Unit 5- Green Skills Class 10 MCQ
Employability skills Class 10 Questions and Answers
- Unit 1- Communication Skills Class 10 Questions and Answers
- Unit 2- Self-Management Skills Class 10 Questions and Answers
- Unit 3- Basic ICT Skills Class 10 Questions and Answers
- Unit 4- Entrepreneurial Skills Class 10 Questions and Answers
- Unit 5- Green Skills Class 10 Questions and Answers
Artificial Intelligence Class 10 Notes
- Unit 1 – Introduction to Artificial Intelligence Class 10 Notes
- Unit 2 – AI Project Cycle Class 10 Notes
- Unit 3 – Natural Language Processing Class 10 Notes
- Unit 4 – Evaluation Class 10 Notes
- Advanced Python Class 10 Notes
- Computer Vision Class 10 Notes
Artificial Intelligence Class 10 MCQ
- Unit 1 – Introduction to Artificial Intelligence Class 10 MCQ
- Unit 2 – AI Project Cycle Class 10 MCQ
- Unit 3 – Natural Language Processing Class 10 MCQ
- Unit 4 – Evaluation Class 10 MCQ